Sina Weibo’s previous HTTP API gateway was built based on Nginx, which brought up a series of problems. After some research, we chose Apache APISIX, which is dynamic, efficient and stable to meet the fast response requirements of the business.
Sina Weibo’s previous HTTP API gateway was built based on Nginx, and all routing rules were stored in Nginx configuration files, which brought a series of problems: long upgrade steps, inflexibility and difficulty in troubleshooting problems when adding, deleting, changing or tracking services. After some research, we chose the closest expected, cloud-based micro-service API gateway: Apache APISIX, which is dynamic, efficient and stable to meet the rapid response requirements of the business.
Background Information
In Sina Weibo, if an operation engineer wants to create an API service, he/she needs to write it in the Nginx configuration file first, submit it to the git code repository, and wait for other operation engineer responsible for the online checkout to confirm the success of the audit before they can push the deployment to the line, and then brutally notify Nginx to reload it, and only then is the service change successful.
The whole process is long and inefficient, and cannot meet the trend of low-code DevOps operation and maintenance. Therefore, we expect to have a management backend portal, where operation engineer can operate all the http api routing and other configurations in the UI interface.

After some research, we chose the closest to the expected cloud-based micro-services API gateway: Apache APISIX.
- Based on Nginx, the technology stack is unified before and after the canary release upgrade, security, stability, etc. are guaranteed.
- Built-in unified control surface, unified management of multiple proxy services.
- Dynamic API call, you can complete the common resource modifications in real time, compared to the traditional Nginx configuration + reload way progress is obvious.
- Rich routing options to meet the needs of Sina Weibo routing.
- Good scalability, support Consul kv.
- Good performance.

Why Did We Choose Custom Development?
In the actual business situation, we cannot use Apache APISIX directly for the following reasons.
- Apache APISIX does not support SaaS multi-tenancy, and there are many upper-layer applications that actually need to be operated and maintained, and each business line development or operation and maintenance student only needs to manage and maintain their own rules, upstreams and other rules, which are not associated with each other.
- When the routing rules are published online, they need fast roll back support if problems arise.
- When creating or editing existing routing rules, we are not so sure about publishing them directly to the wire, and then we need it to be able to support canary release to a specified gateway instance for simulation or local testing.
- The need for API gateways to be able to support Consul KV-style service registration and discovery mechanisms.
None of these requirements are currently supported built-in by Apache APISIX, so custom development is the only way to make Apache APISIX truly usable within Weibo.
What Did We Change in the Control Plane of Apache APISIX?
For our custom development, we used Apache APISIX version 1.5, and Apache APISIX Dashboard compatible with Apache APISIX version 1.5.
The goal of custom development is simple and clear, that is, completely zero code, UI, all seven layers of HTTP API service creation, editing, updating, up and down and all other actions must be done on the Dashboard. Therefore, in the actual environment, we forbid development and operation and operation engineer to call APISIX Admin API directly. If we skip the Dashboard and call APISIX Admin API directly, it will lead to the gateway operation not being audited at the UI level, so we cannot take the workflow, and naturally, there is not much security to speak of.
There is a slightly special case, operations and maintenance need to call the API to complete the bulk import of services, you can call the H5 Dashboard API to complete, so as to comply with the unified workflow.
Support Saas-based Services
A complete database of product lines and business lines is available at the enterprise level, and each specific product line and business line can be represented by a saas_id value. Then, before creating the gateway configuration data for insertion into the ETCD, a saas_id value is plugged in and all the data has a SaaS attribution in terms of logical attributes.
Users, roles and the actual product line of operation are then associated with the following correspondence.
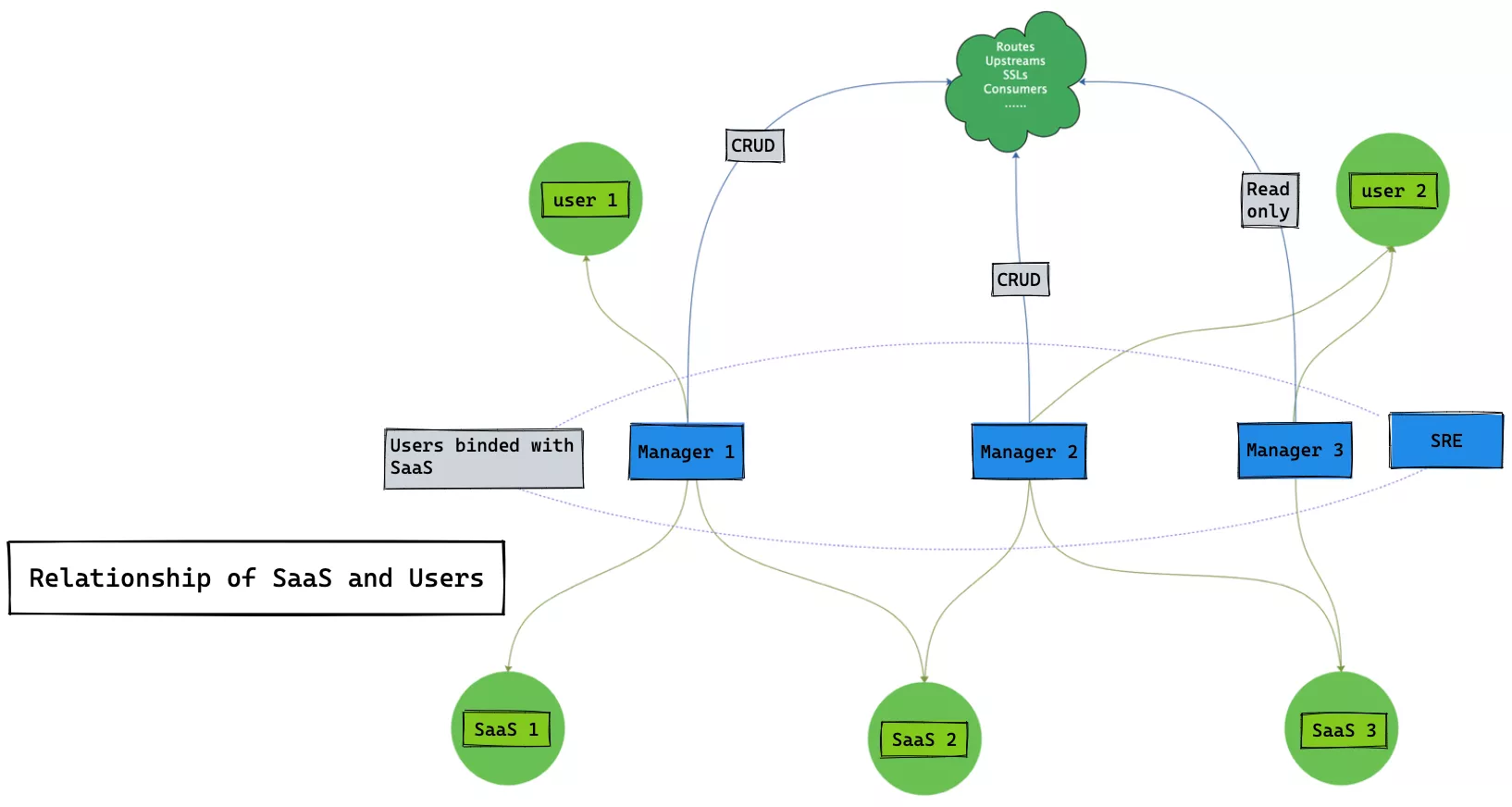
A user can be assigned to undertake different operations and maintenance roles to manage and maintain different product lines of services.
The administrator role is very easy to understand, the core role of operation and maintenance services, for service addition / deletion / update / check; in addition, we have the concept of read-only users, read-only users are generally used to view the service configuration, view the workflow, debugging and so on.
Add Audit Function
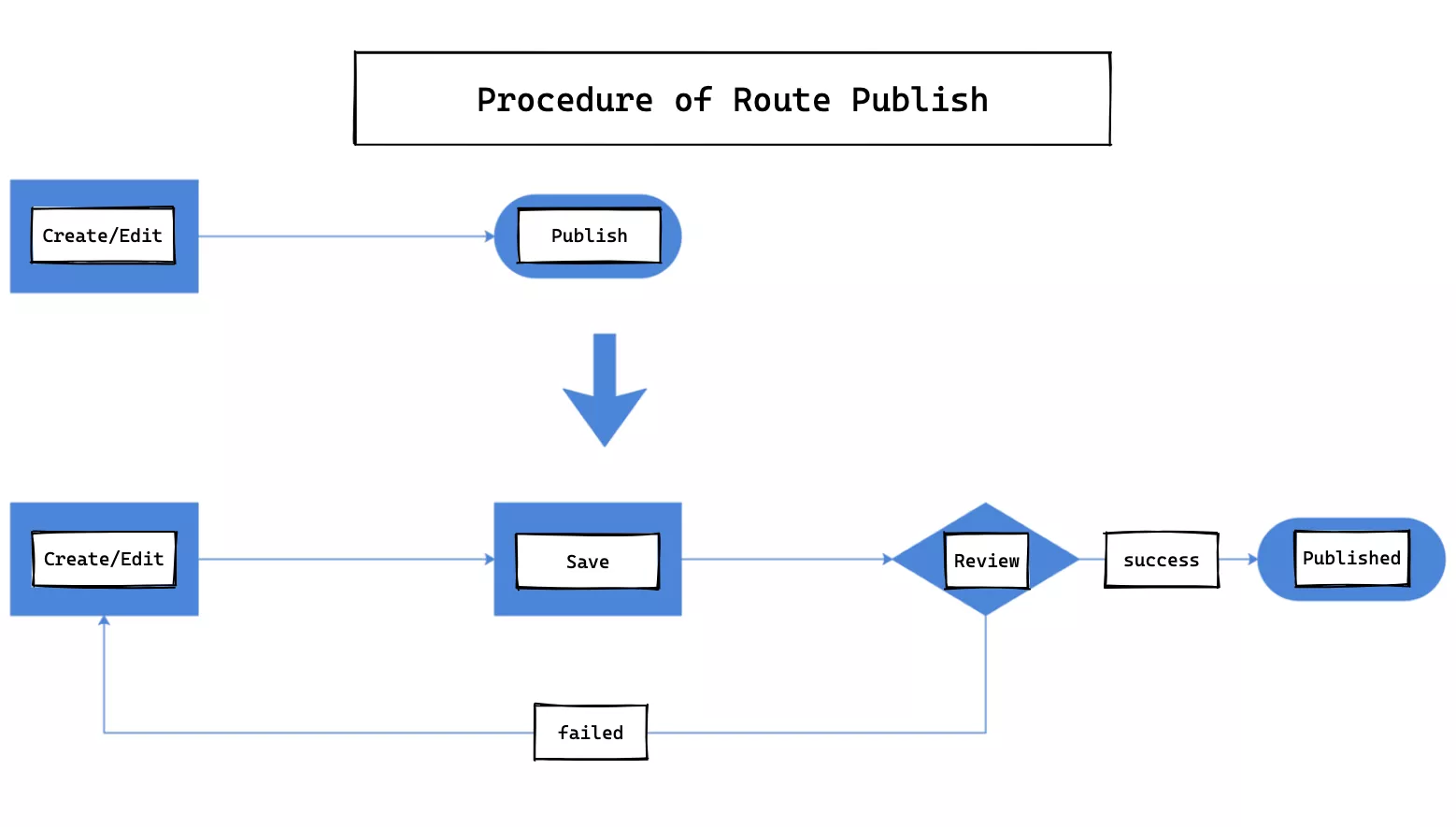
In the open source version, a route can be published directly after it is created or modified.
In our custom version, after a route is created or modified, it needs to go through an audit workflow before it can be published, which lengthens the process, but we think it is more credible to publish after the authorization is reviewed at the enterprise level.

When creating routing rules, they must be reviewed by default. To take into account efficiency, when entering new services, you can choose the no-review, fast-publishing channel and click the publish button directly.
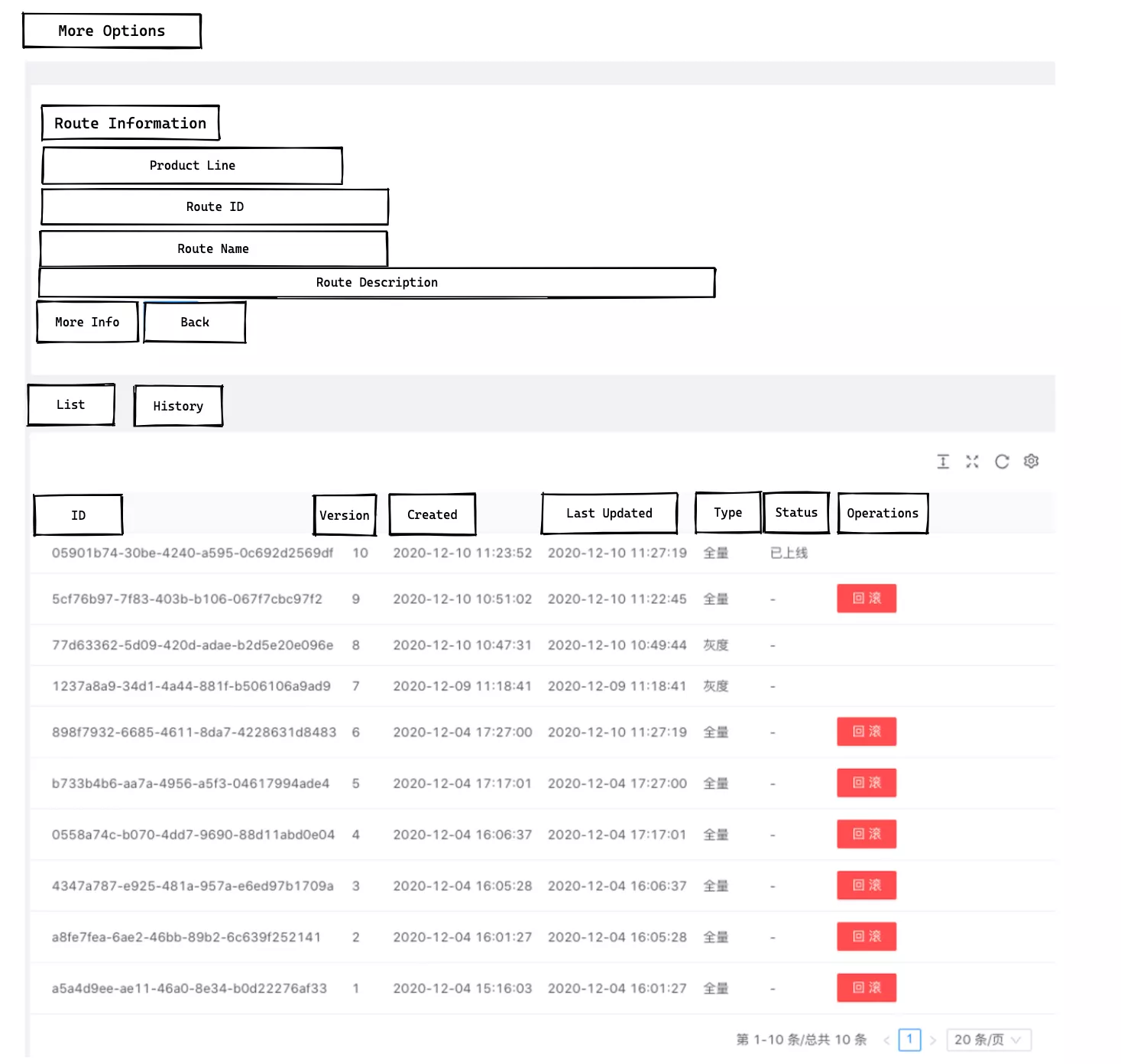

When an important API route has problems after a certain adjustment rule release goes live, you can select the previous version of the routing rule for a quick roll back, with the granularity of a single route roll back that will not affect other routing rules.
The internal processing flow of a single route roll back is shown in the following figure.
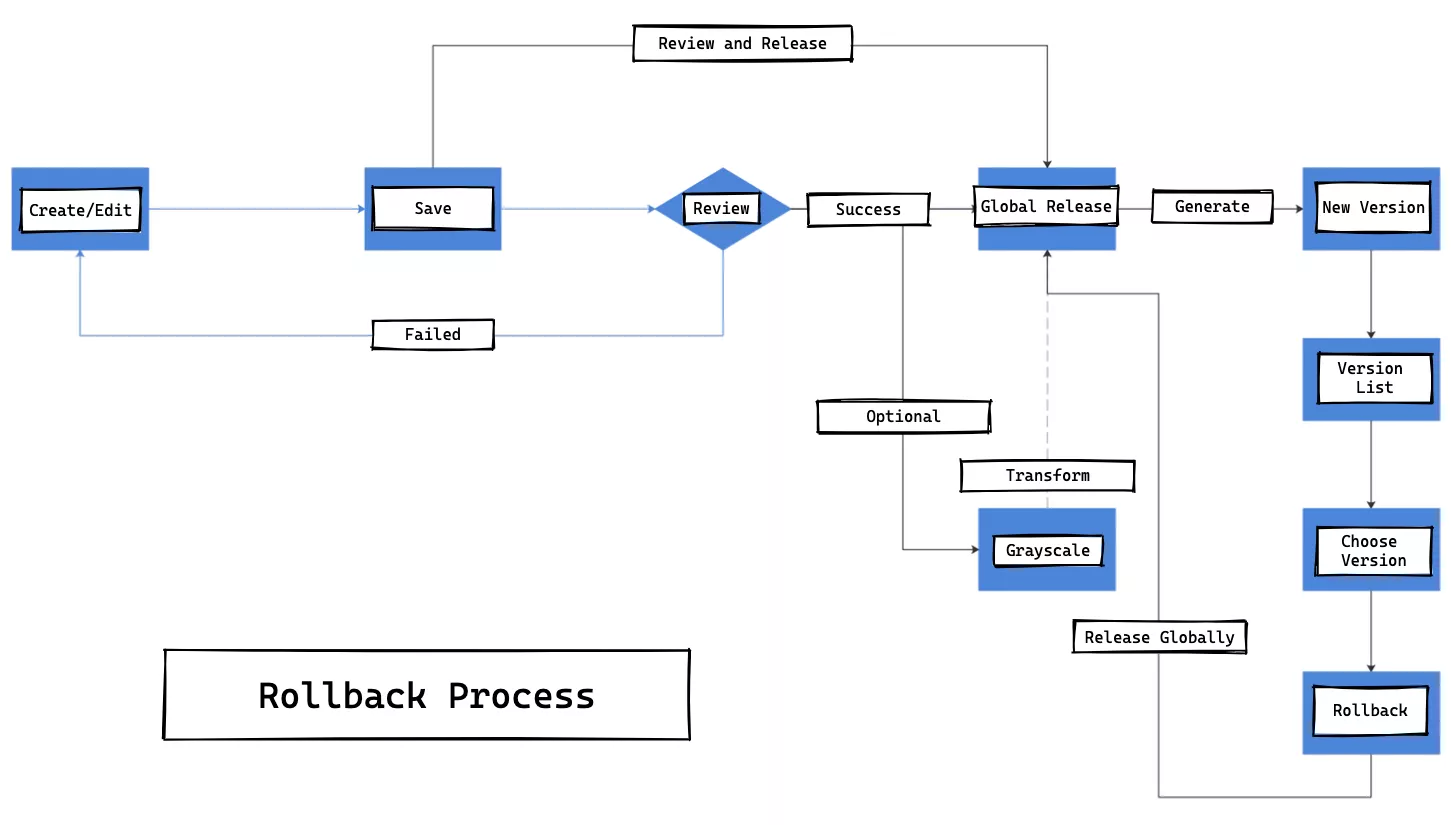
We need to create version database storage for each release of a single route. This way, when we do a full release after the audit, each release will generate a version number and the corresponding full configuration data; then the version list grows. When we need to roll back, go to the version list and select a corresponding version to rollback; in a sense, the roll back is actually a special form of full release.
Support Canary Release
Our custom-developed canary release feature is different from what the community generally understands as canary release, and is less risky compared to full deployment. When a change to a routing rule is large, we can choose to publish and take effect only on a specific limited number of gateway instances, instead of publishing and taking effect on all gateway instances, thus reducing the scope of the release, lowering the risk, and enabling fast trial and error.
Although canary release is a low-frequency behavior, there is still a state transition between it and full volume release.
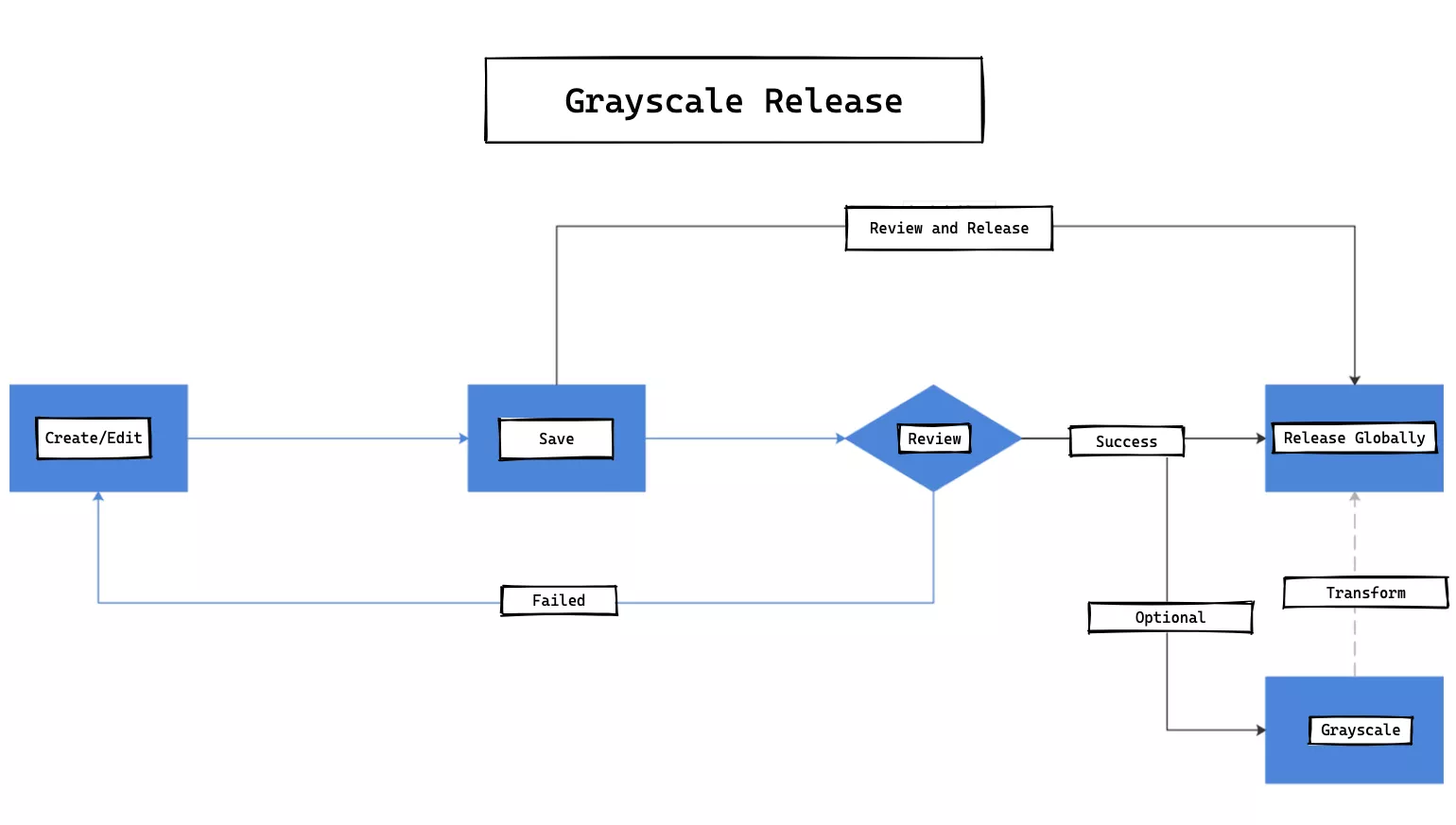
When the percentage of canary release decreases to 0%, it is the state of full release; when the canary release rises to 100%, it is the next full release, and this is its state transition. The full canary release feature requires some API support exposed on the gateway instance in addition to the administrative backend support.
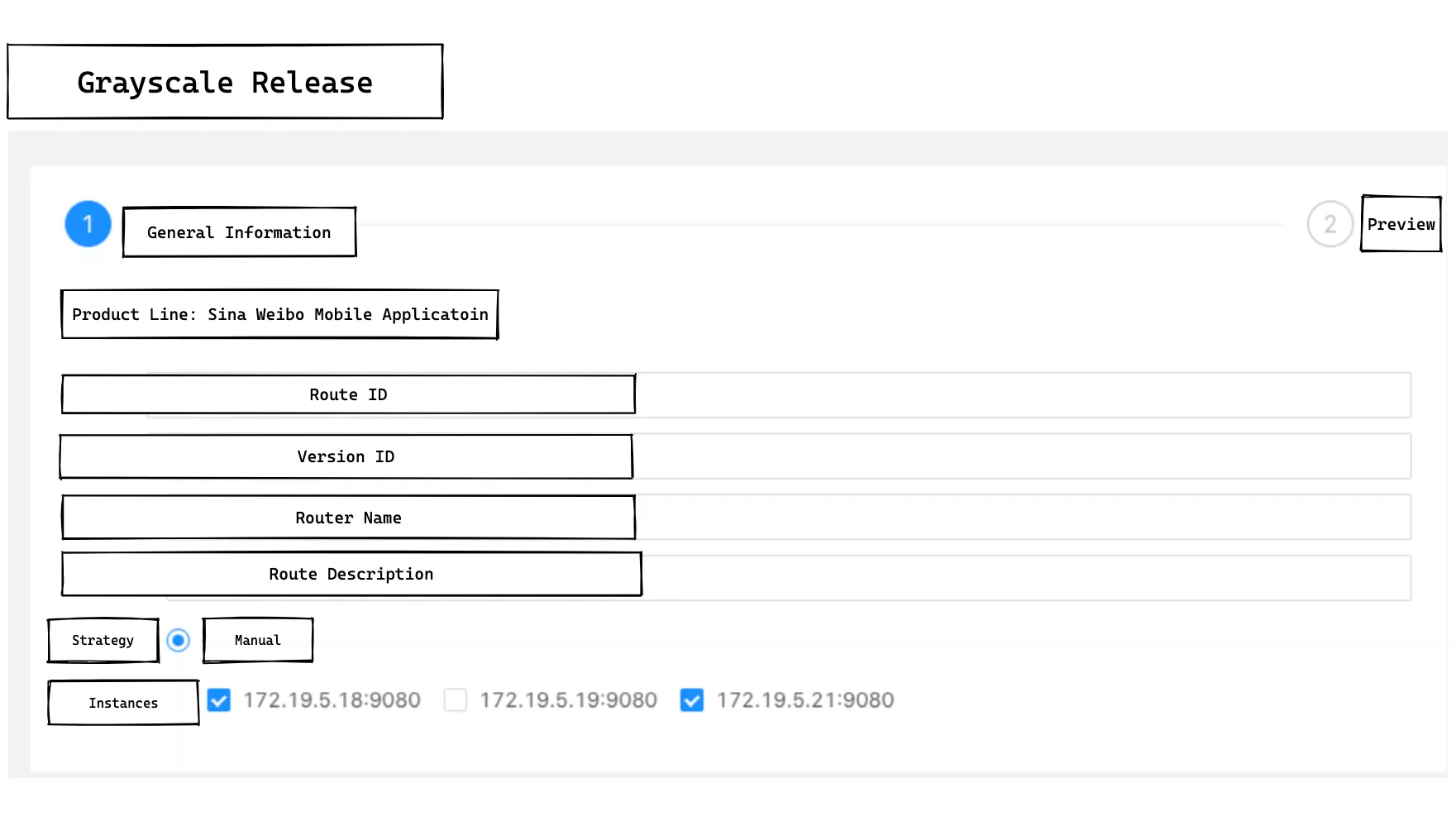
The above screenshot shows the screenshot when operating canary release to select a specific gateway instance.
The full canary release feature requires some API support exposed on the gateway instance in addition to the administrative backend support.


Canary release API fixed URI, the unified path is /admin/services/gray/{SAAS_ID}/ routes. Different HTTP Method presents different business meanings, POST means create, DELETE means to stop canary release, GET means to view.
Activation Process
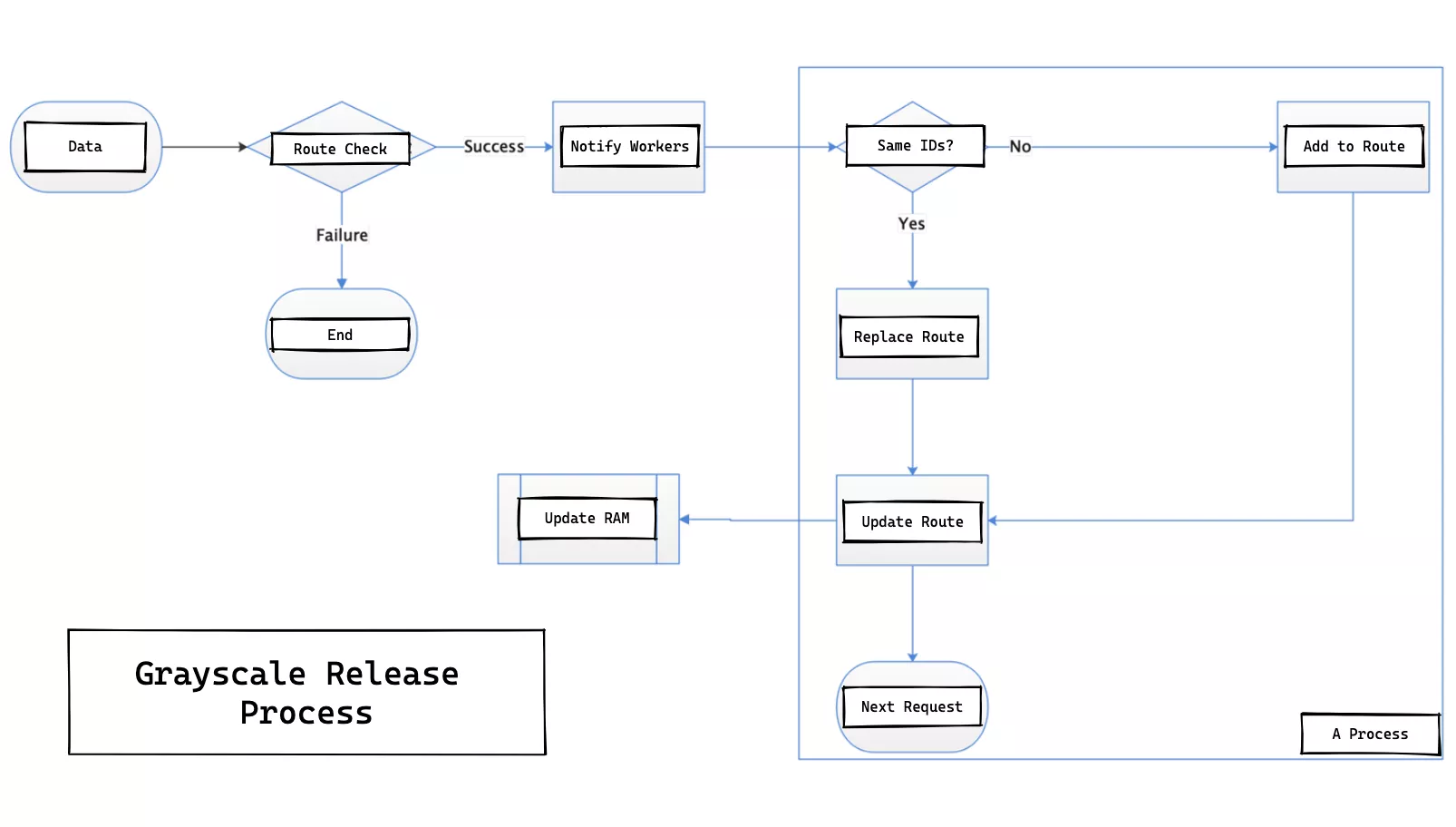
An API is published from the gateway level, and after receiving the data the worker process checks the legitimacy of the data sent, and the legitimate data is broadcast to all worker processes via events. Then the canary release API is called and the canary release rules are added and take effect when the next request is processed.
Deactivation Process
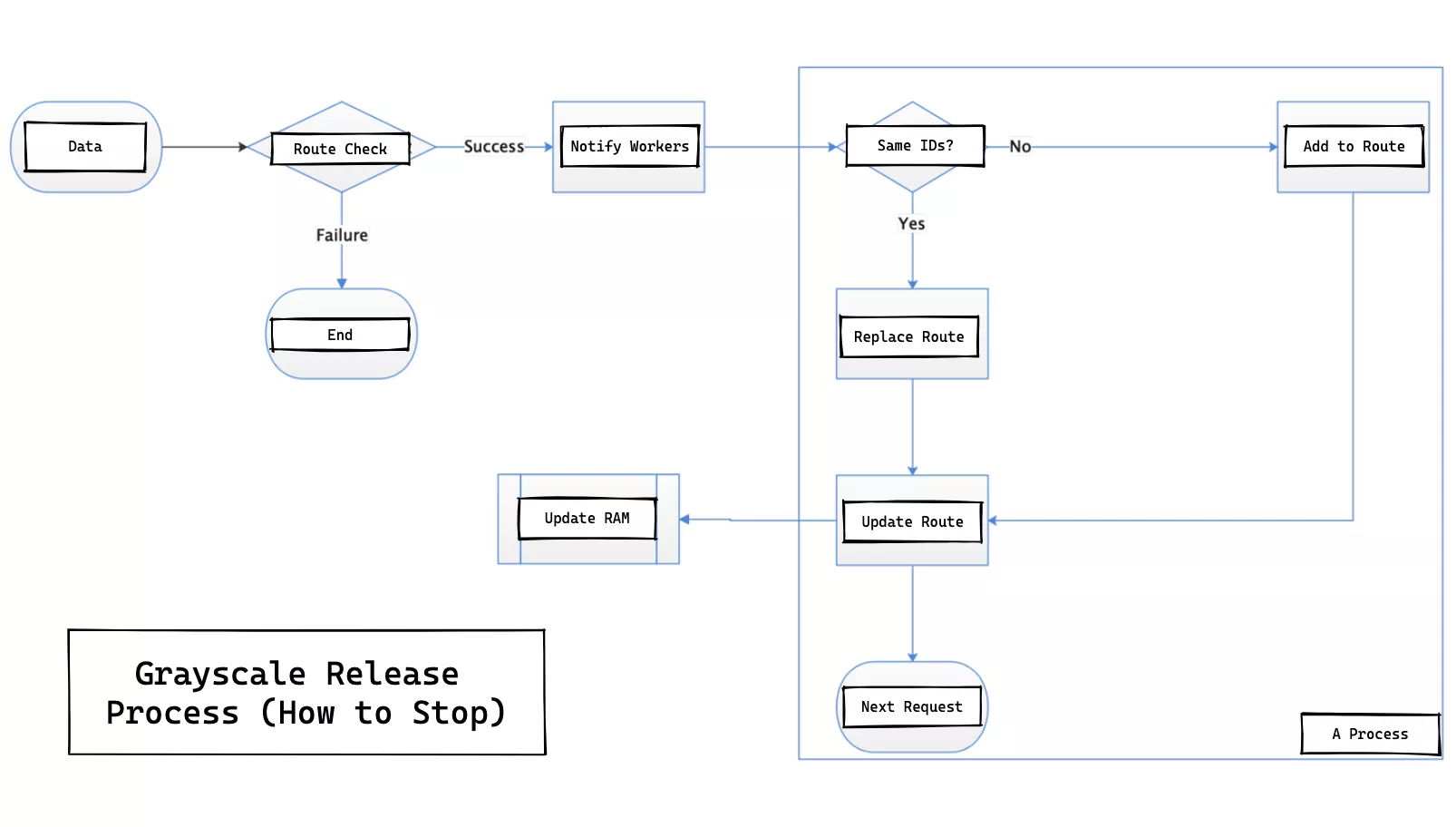
The deactivation process is basically the same as the canary release distribution process. The API for canary release distribution is called by the DELETE method and broadcasted to all work processes. If it exists in the route table, delete it and try to restore it from the ETCD. If the canary release is deactivated, make sure that the original ETCD can be restored without affecting the normal service.
Support Fast Import
In addition to supporting the creation of routes on the management page, many operation engineer are still more accustomed to using scripts to import. We have a large number of HTTP API services, and it would be very time-consuming to manually enter them one by one. If you import through scripts, you can reduce a lot of service migration resistance.
By exposing the Go Import HTTP API for the management backend, the operation engineer can fill in the assigned token, SaaS ID and related UIDs in the ready-made Bash Script file to import the services into the management backend more quickly. The subsequent operation of importing services still needs to be done in the management backend H5 interface.

What Did We Change in the Data Plane of Apache APISIX?
Custom development based on the Apache APISIX data surface requires a number of code path rules to be followed. In particular, the code for the Apache APISIX gateway and the custom code are stored in separate paths, and the two work together and can each be iterated independently.


Modification of Installation Package
So when packaging, not only custom code, but also dependencies, configuration, etc. all need to be packaged together for distribution. As for the output format, you can either choose Docker or type it into a tarball, as required.
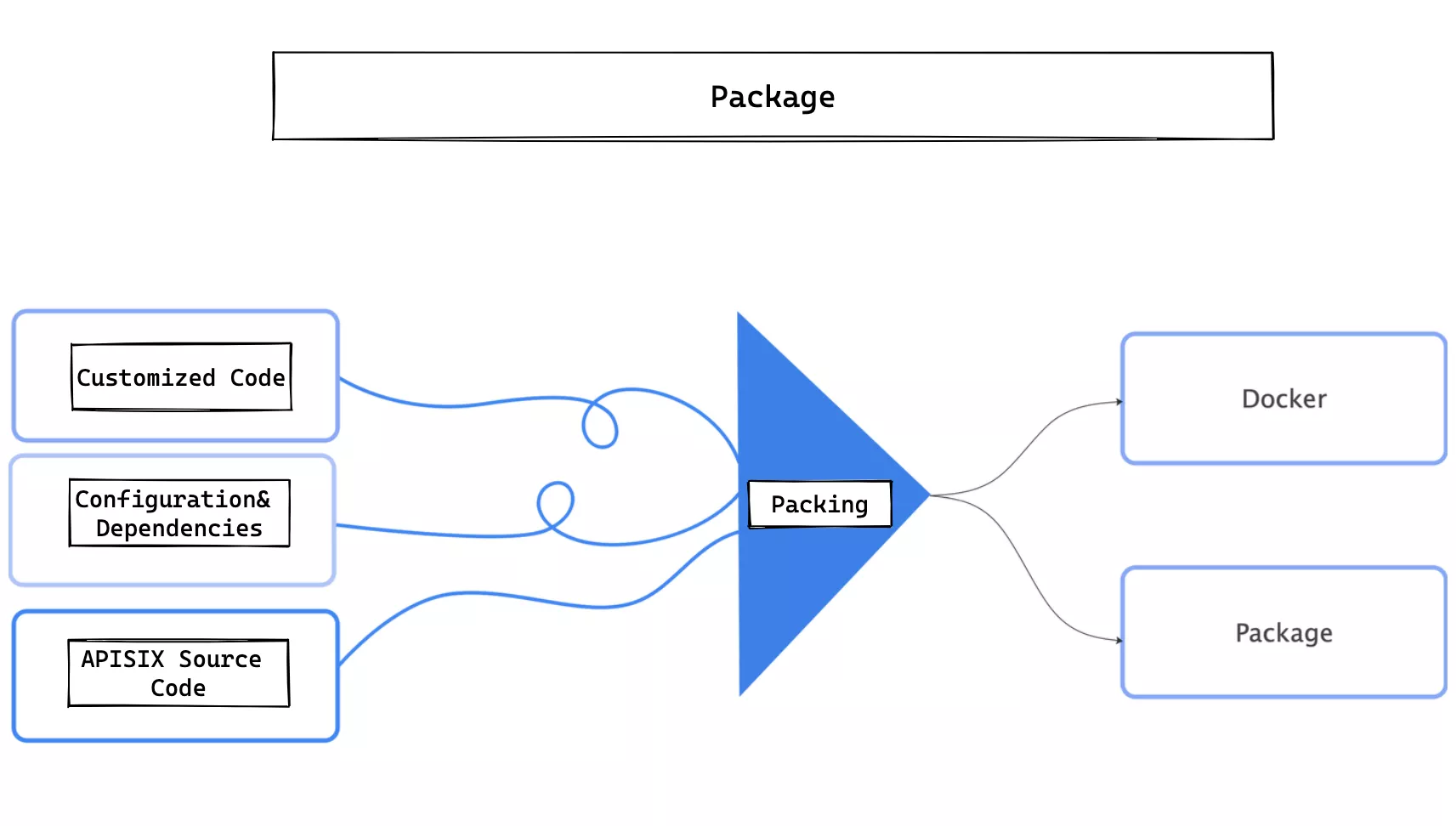
Custom Development of Code
Some custom modules need to be loaded first when they are initialized, so that the code intrusion into Apache APISIX becomes minimal, requiring only modifications to the Nginx.conf file.

For example, if you need to stuff an upstream object with a saas_id attribute field, you can call the following method at initialize time.
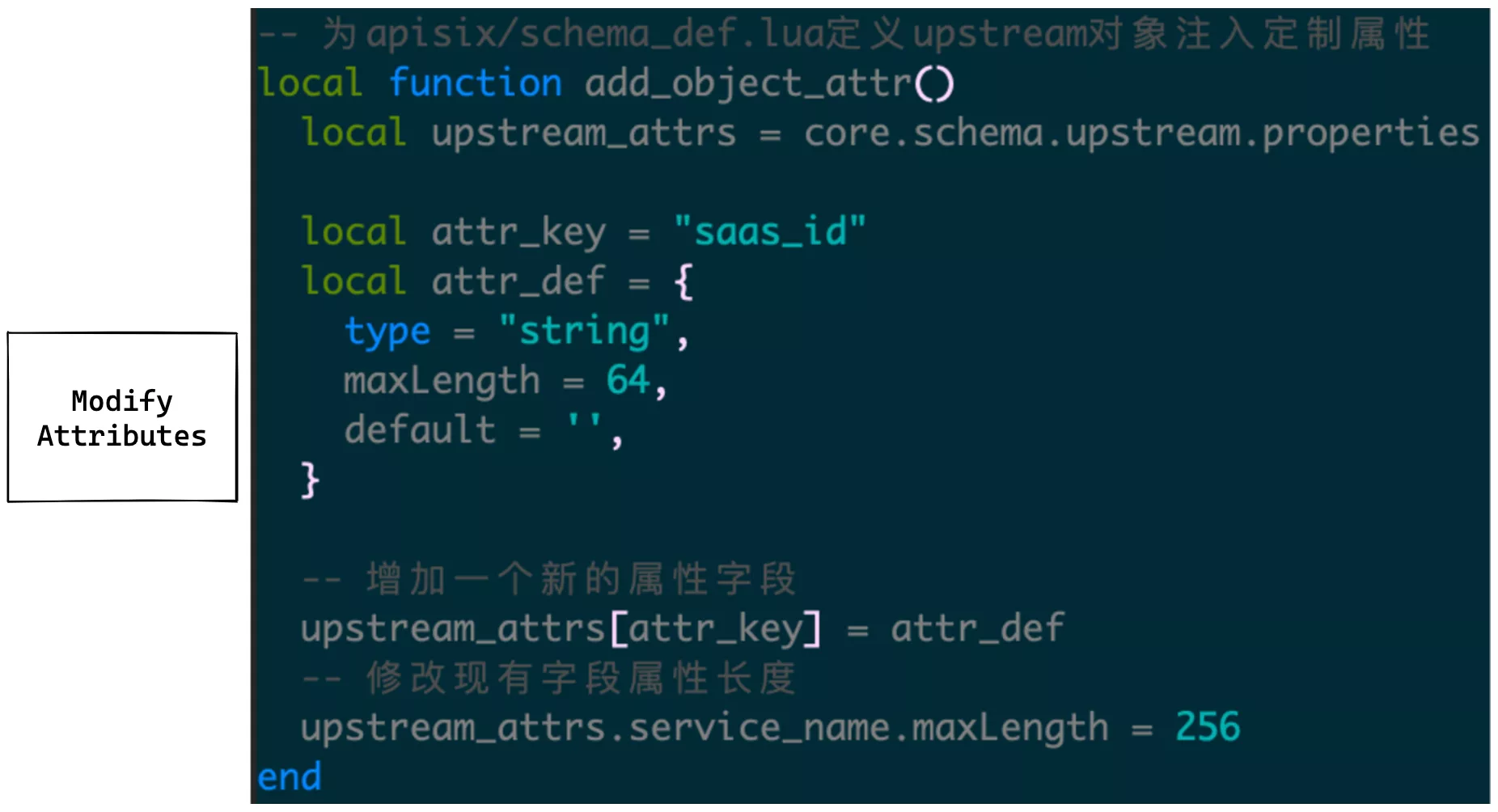
You need to be called in the initworker_by_lua* phase to complete the initialization for similar modifications.
Another scenario: how to directly rewrite the implementation of a currently existing module. For example, if you have a debug module and now you need to refactor its initialization logic, i.e. rewrite the init_worker function.

The advantage of this approach is that it not only keeps the original physical API files intact, but also adds custom API-specific logic rewrites, thus reducing the cost of later code management and bringing great convenience for subsequent upgrades.
If you have similar needs in a production environment, you can refer to the above approach.
Support Consul KV
Currently, most of Weibo services use Consul KV as a service registration and discovery mechanism. Previously, Apache APISIX did not support the Consul KV method of service discovery mechanism, so a consul_kv.lua module needs to be added to the gateway layer, and a UI interface needs to be provided in the management backend as follows.
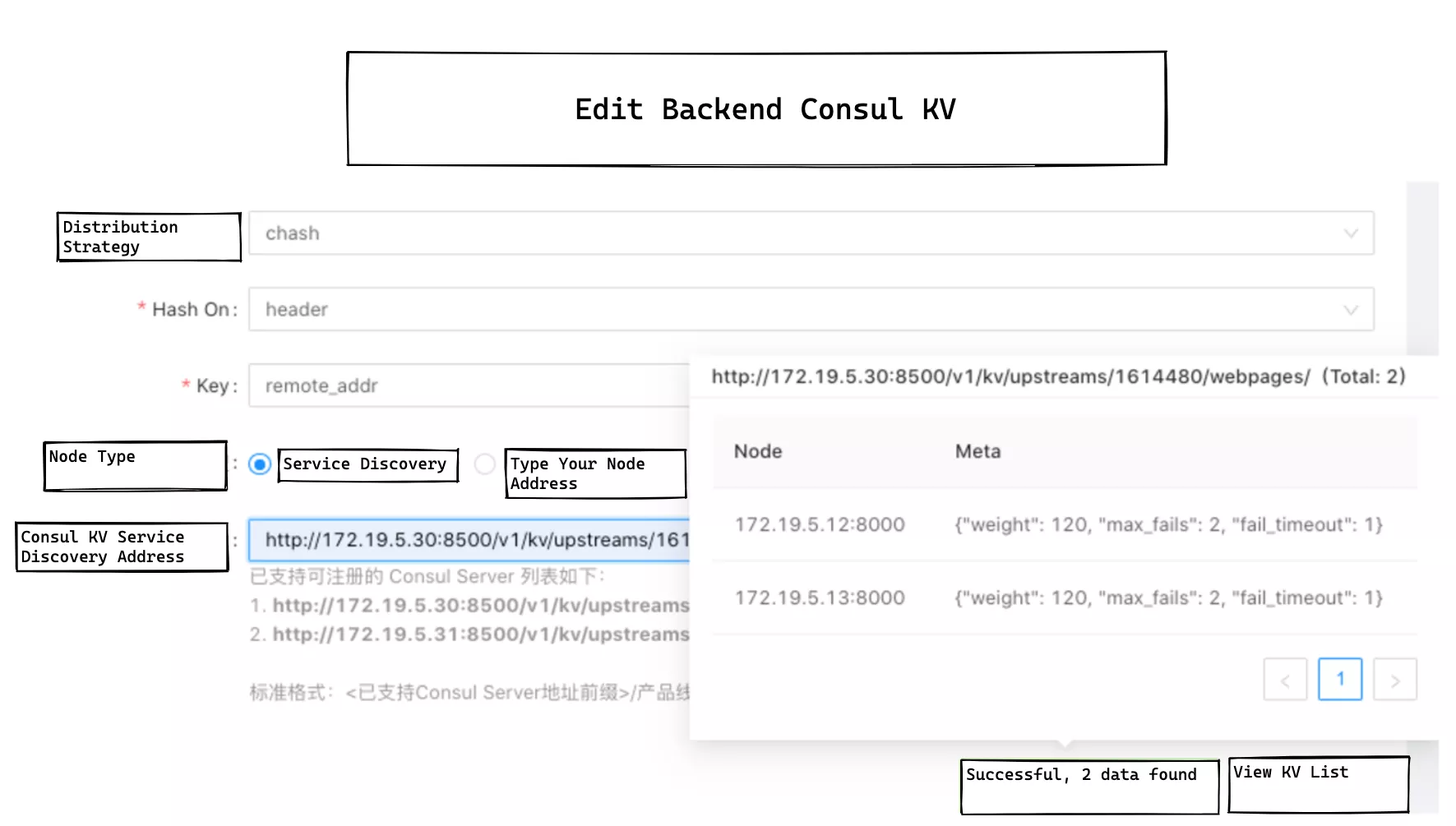

In the upstream list in the console, everything is filled in at a glance, and the metadata of all registered nodes is automatically presented when the mouse is moved over the registered service address, which greatly facilitates the daily operation of our operation engineers.
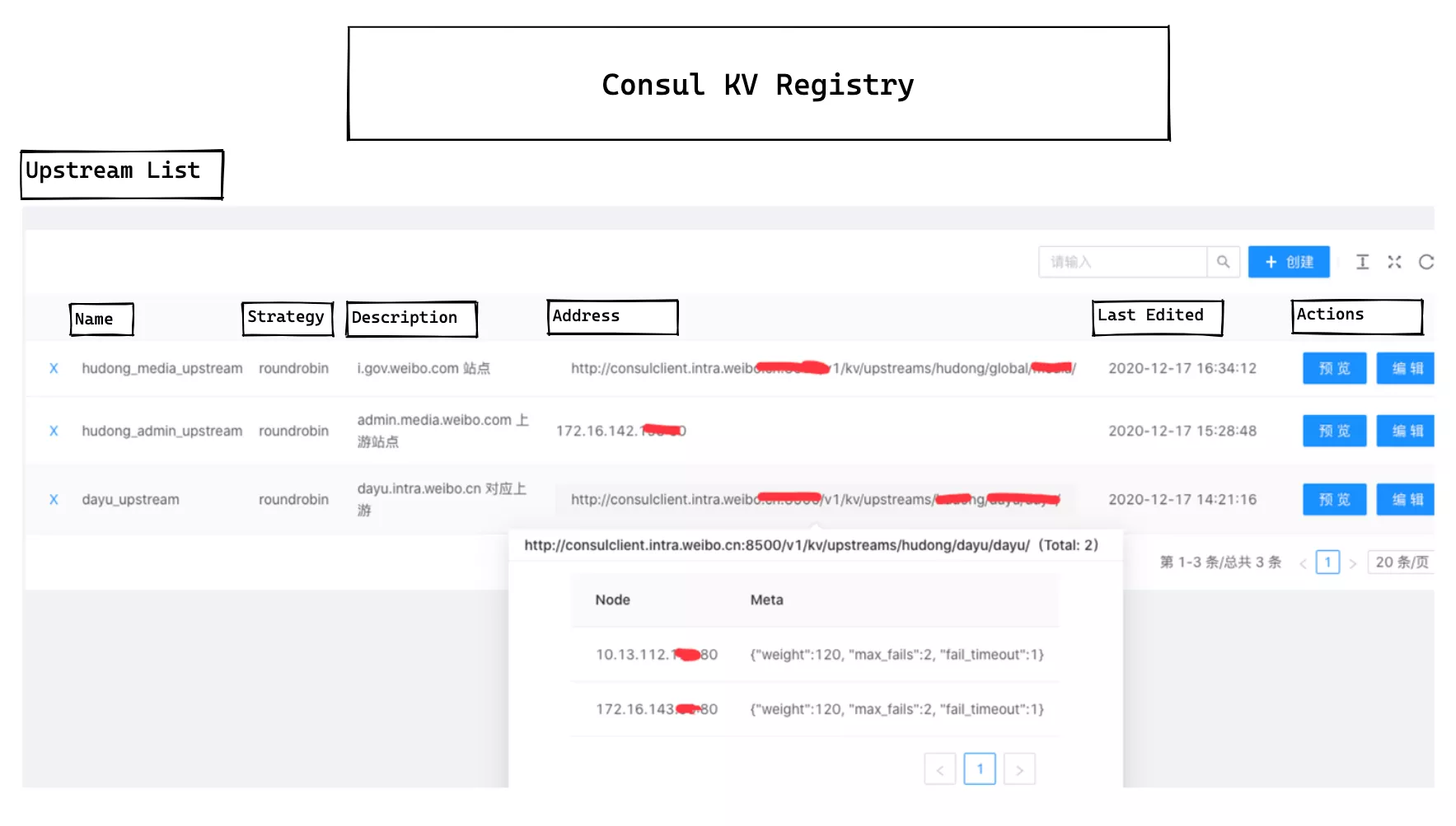

The consul_kv.lua module is relatively simple to configure at the gateway level, supporting multiple connections to different Consul clusters at the same time, but this is also due to the requirements of the actual environment.
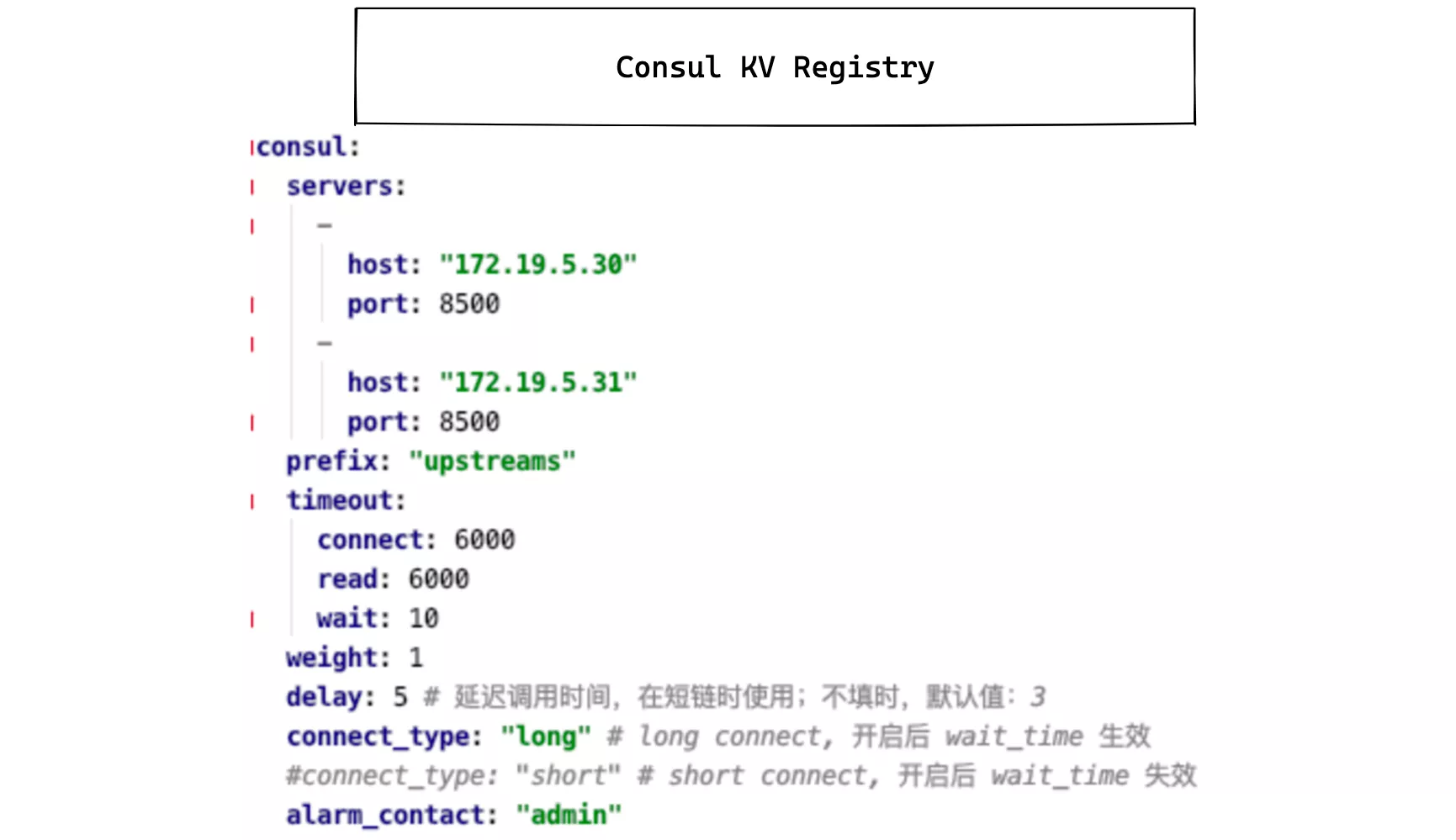

This code has now been merged into the APISIX master branch and is included in version 2.4.
The module's process model uses a subscription publishing model, where each gateway instance has one and only one process that polls multiple Consul service clusters with long connections and broadcasts new data to all business sub-processes as it becomes available.
Problems Encountered during Customization
High Costs for Migration
At the operation and maintenance level, we are actually facing a problem of migration cost.
Any new thing appeared, used to replace the existing foundation, will not be a smooth ride, but need to go through a period of time slowly familiar with, improve knowledge, and then keep trial and error, slowly move forward, and gradually eliminate all kinds of doubts in our minds. Only after a period of stable operation and various problems have been solved, will the next step of more rapid replacement phase be entered. There is no doubt that the use of APISIX in Weibo is still in the stage of gradual advancement, and we are still familiarizing ourselves with it, learning it, and gaining a deeper understanding of it, while solving various migration problems in order to find the best practice path.
For example, during the migration process, you need to import various upstream and routing rules from the Nginx.conf file into the gateway system administration backend one by one, which is a very tedious and manual process.

At the same time, we will also encounter Nginx various complex variable judgment statements, at present, we mainly find one to solve one, and continue to accumulate experience.
High Costs for Upgrades
High level of customization, resulting in higher costs for subsequent upgrades. We are currently experiencing the same problem as everyone else, many people should be based on version 1.x Apache APISIX how to upgrade to 2.0, we also have a Dashboard of private custom development, the subsequent upgrade costs should be higher.
Feeding the Community
The final part is about the Apache APISIX community. We have been thinking about how to feed features of interest to the Apache APISIX community for everyone to use and modify together.
It is an objective fact that our custom development is driven primarily by actual internal Weibo requirements, and there is some variation from the evolution driven by the Apache APISIX community. However, excluding code that contains sensitive data, there are always common needs at the code level for more general functionality that the enterprise and open source communities can push together to make more stable and mature. For example, a common Consul KV service discovery module, handling of some highly available profiles, and fixes for other issues.
These common requirements are typically polished internally for a period of time until they fully satisfy internal requirements, and then gradually submitted to the community open source branch, but this also requires a process.