
本文从应用 APISIX 后的调整与实践困难角度入手,为大家带来了 vivo 基于 APISIX 的企业实践细节。
分享嘉宾赵旭,vivo 互联网架构师,主要专注于基础架构研发方向。
Apache APISIX 在这两年已经受到了国内很多知名企业的信赖,并纷纷开始在实际生产环境中应用 APISIX。在这个过程中也包揽了很多不同行业的企业用户,比如金融行业的众安保险和安信证券,国产头部车企的吉利和小鹏汽车。其实在国产手机领域中,也有一些头部企业用户在使用,比如 vivo。
vivo 是从去年年中开始在业务生产中正式使用 APISIX 来替换之前传统的 NGINX。目前 APISIX 在 vivo 业务架构的实践和场景支持上都表现得十分出色:
高可用性:上线至今没有出现重大故障,系统可用性超过 99.99%;
高性能:承载较大线上流量,服务于较多业务。线上目前转发流量接近百万级 QPS,目前仍处于持续增长的过程中;
功能丰富:基本覆盖了常见的 NGINX 代理场景,50% 的业务已经迁移到 APISIX 集群;
支撑了云原生的建设和发展:有效支撑和推动了公司容器化进展,支撑容器平台的物理机器已有万级规模,40% 的业务已经从物理机虚拟机迁移到容器平台。
基于 APISIX 架构设计与定制调整
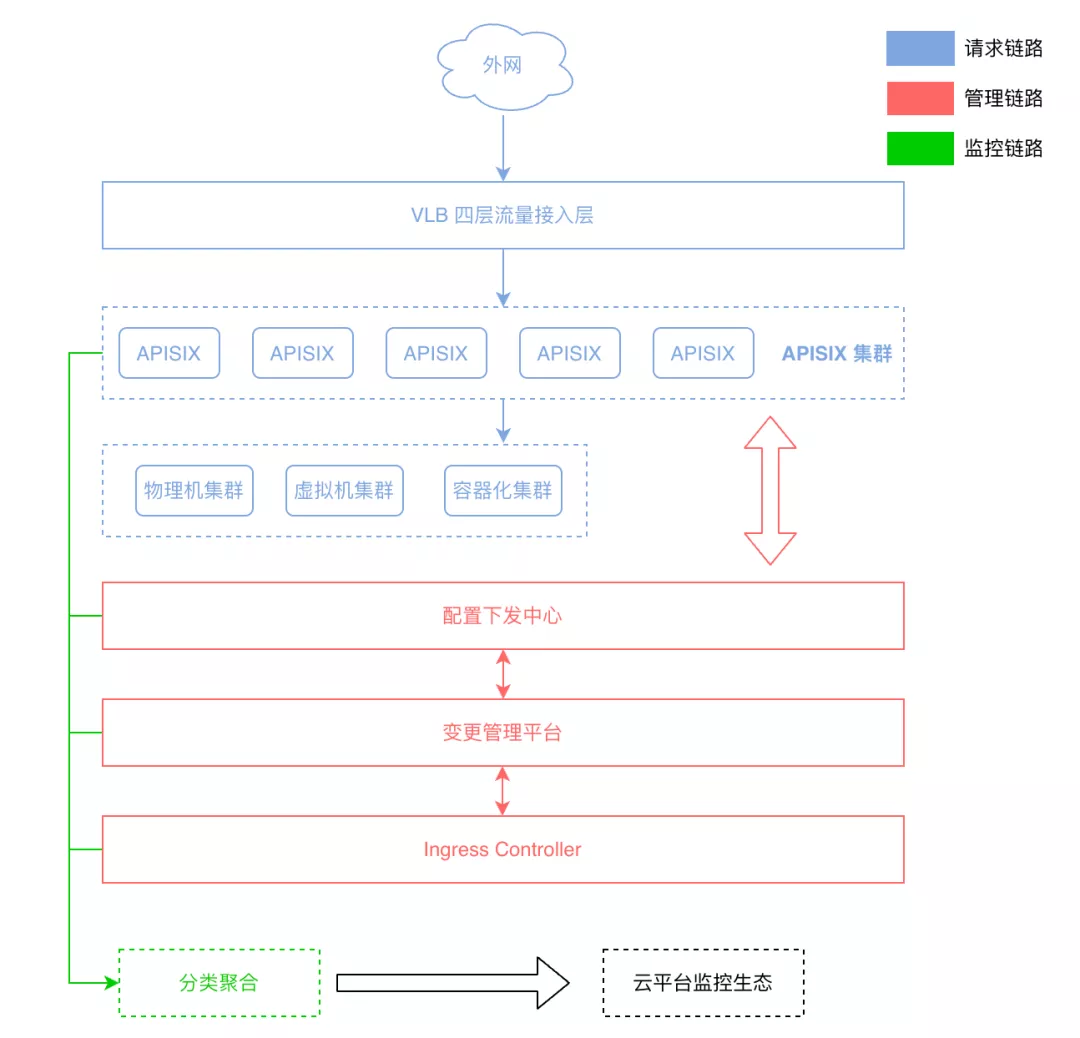

从上图架构中可以看到,在网关层面我们已经实现了“四层+七层”的代理模式。其中四层网关我们是用 LVS+DPDK 的方式来实现的,流量从外网进入四层网关后会转换到七层网关。而七层网关就是 APISIX 集群,目前这套 APISIX 集群已经实现了容器、物理机、虚拟机等容器混合流量部署的接入功能。
图中红色部分,则是我们正在使用的一些自研和开源项目,并借助这些项目实现整个流量转发体系。另外在架构中,我们还实现了 APISIX 集群拆分的管理功能。
这套架构基于 APISIX 开源版本我们也进行了一些调整,主要是在控制面和数据面进行了更贴合内部业务的改造。
配置管理与发布改造
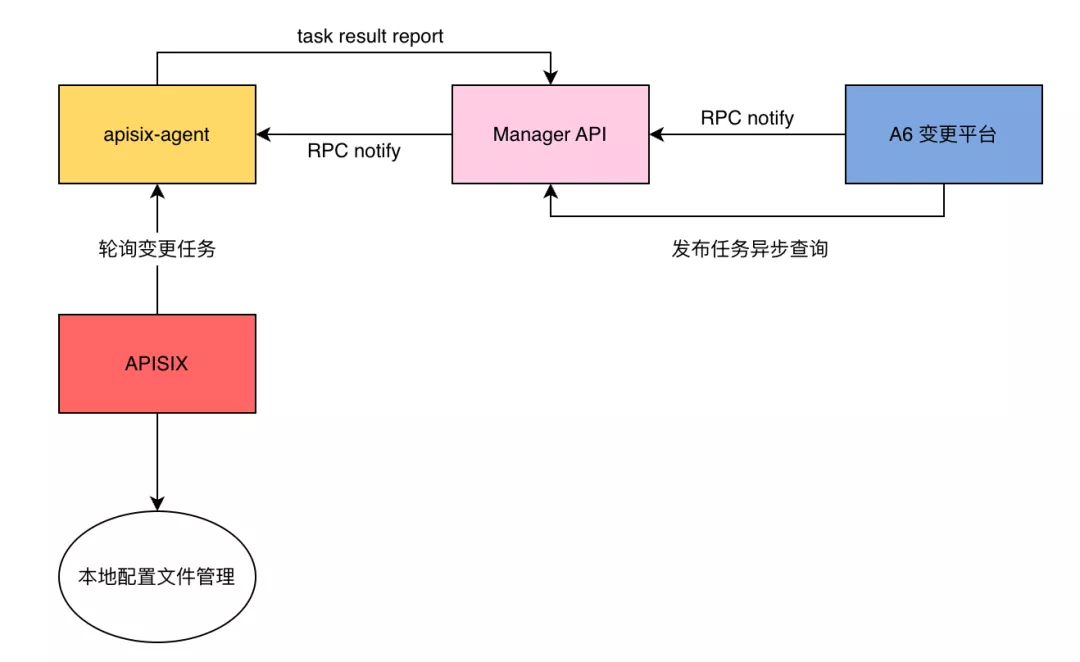
当业务从 APISIX 变更平台配置好相关数据后,变更平台会通过 RPC notify 的方式发送给 Manager API。之后 Manager API 会通过 RPC notify 方式发送给部署在 APISIX 集群中的 apisix-agent。然后 APISIX 会通过 privilege 特权进程,定时轮询 apisix-agent 去批量获取变更任务。
之后 APISIX 通过共享队列的方式,由特权进程通知给各个实际的 worker 来实现内存上的变更。变更完成后,worker 会将相关的配置信息进行一个落盘处理。当整个任务完成后, APISIX 会把相关结果通知传送给 apisix-agent 并传递给 Manager API。
本身这套流程是一个异步查询,对于配置是否完全生效或者任务是否成功,都是通过轮询接口进行查询。可以看到上述流程中,我们对开源 APISIX 进行了如下的变动:
去掉 etcd 组件,自研实现了基于 APISIX 的 A6 配置管理系统。
之所以去掉 etcd 组件,是因为 etcd 本身还是一个偏内存的数据库,不适用于多维度资源的查询;同时对于我们本身业务而言,etcd 的修改事件模式(主要是删除)具有不可重入性,一旦删除相关资源,就无法再进行重复性操作;最后就是考虑到单独增加一个系统组件(且处于核心地位),在大量 watch client 下的系统维护复杂度会大量增加,因此在我们的改造架构中删除了 etcd。
自研 apisix-agent 组件。
在引入 APISIX 之前,我们团队对于 OpenResty 和 Lua 的使用经验基本为 0。所以考虑到已经去掉 etcd 的前提下,我们团队确实不具备能够改造 APISIX 核心底层技术的能力,所以通过自研 apisix-agent 组件,来简化现有 APISIX 的一些能力,降低我们内部使用上的一些复杂度,从而达到复杂性和稳定性之间的权衡。
实现 APISIX 资源配置文件本地落盘。
这一点主要是我们在设计时,希望数据面可以独立运行而不是去依赖于一个控制中心,减少连带影响。这样的话,当 APISIX 启动时就可以从配置中心全量拉取,也可以直接从本地落盘的文件目录进行拉取。在这种方案下,大大提高了数据面的独立性与系统的健壮性,同时对于问题的排查也带来了更清晰的路径展示。
增加“变更任务、结果回调”的上报机制。
整个流程的后半段,其实都是在执行这种上报机制。之所以制作这种逻辑,是为了保障像路由和上游等核心资源的时效性。一旦出现那种你以为资源下发成功但实际没成功的现状,就必然会导致一段时间的流量影响。这套逻辑就可以保证 APISIX 上所有的 worker 都把需要的资源变动更新到了对应内存中。
集群拆分管理改造
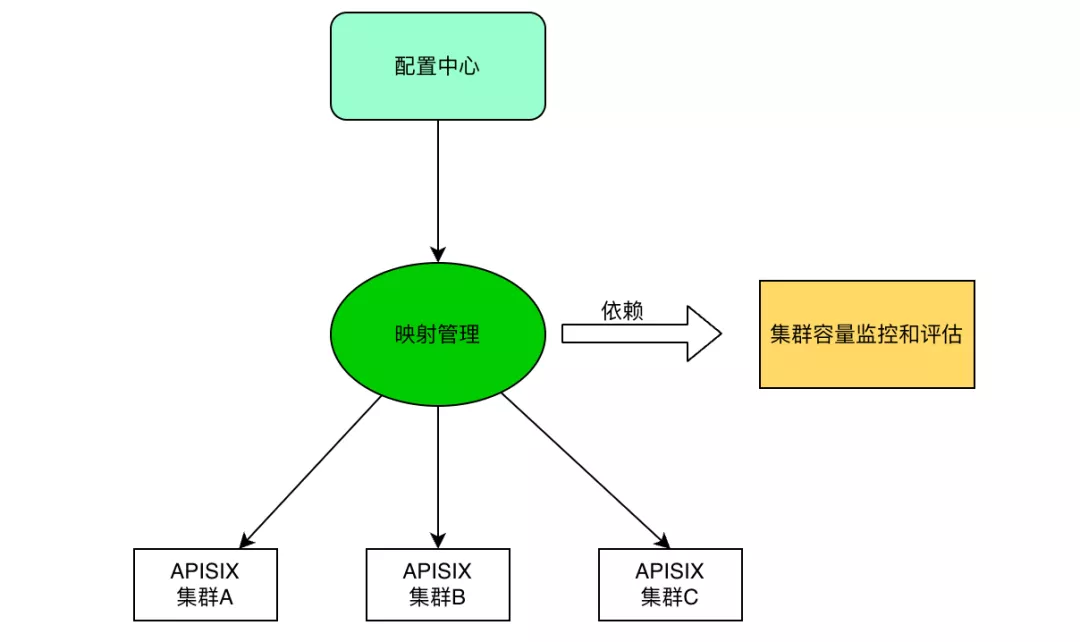
APISIX 开源版本中是不支持集群管理功能的,基本上所有业务都共用一个 etcd。但是对于我们这种中大型企业来说,业务场景与业务逻辑都十分复杂。在这种情况下如果使用这种大一统的集群方式,在业务运行过程中很容易出现不可控的场景。其次,随着业务复杂度的提升,有些业务就不可避免地会用到更复杂的插件,一旦数量变多,对于整个集群的性能也会造成一定影响。
基于以上考虑,我们决定将 APISIX 进行集群拆分化的管理,从而实现业务和服务集群的精细化管理。这样就可以实现不同的域名或业务通过映射管理等各种方式,分配给不同的 APISIX 集群,从而实现 APISIX 集群上的配置隔离。同时还能控制故障域,对于业务复杂度也能起到一个有效的支撑。
如果业务过于复杂,就可以给它单独分配集群,不会影响其他业务。有效降低了 APISIX 非转发层面所造成集群负载,包括配置下发、高频容器节点变更以及健康检查所带来的负载影响。
新增 Intel QAT HTTPS 加速卡
根据国家工信部的相关要求,外网流量必须要走 HTTPS 协议。作为一个基于 TLS 的 HTTP 加密协议,HTTPS 的加解密过程对于 CPU 的负担是比较大的。
我们内部进行过一个统计,如果纯转发 HTTP 和 HTTPS 两种,同样的路由和其他相关配置齐平的情况下,HTTPS 只能承载大概 HTTP 的 1/8 到 1/10 左右。因此 HTTPS 的加解密对于性能影响还是非常大的,因此我们重新编译了 OpenResty 模块。
主要操作就是在 NGINX 代码中 Patch 了 Intel QAT 模块,通过 SSL 异步解密方式,将加解密的过程交给了 QAT 卡进行。从而释放了 CPU,增大了单机 HTTPS 承载的 QPS。通过引入这套模块,单机 HTTPS 承载量提升了一倍左右。
落地 APISIX 的问题与解决方案
支持容器化,自研 Ingress 组件
为了让这套架构符合公司的容器化发展,我们还自研了一套内部的 K8s-ingress 组件,这个组件的作用就是将 K8s 节点的变更通知到 APISIX 中。
在之前公司内部已经利用 Calico 方案实现了容器与 IDC 机房的网络互通。在这种情况下,如何快速稳定地将变更通知到 APISIX 进行流量转发,是接入 K8s 的重要一环。
因此我们在调研过一些 K8s Ingress 实现方案之后,基于公司的业务场景和发展,最终选择了自研开发。主要考虑了以下几点:
- 适配改造的异步推送配置变更机制。前文介绍过的异步轮询机制其实是比较复杂的,因此为了适配这套机制,我们选择了用自研组件去配合。
- 适配多套 K8s 集群事件处理通知。由于公司业务丰富,我们不可能只部署同一套 K8s 集群。因此从稳定性与可控管理层面因素考虑,我们在这里也进行了多集群场景的适配,保证多集群的变更能正常通知到 APISIX 中。
- 适配复杂的业务场景。比如满足一个 Server 监听多个端口(涉及不同协议)的场景,或者是将 Dubbo、gRPC 等其他 RPC 框架服务器接入 K8s 的场景,这些都需要单独开发一套逻辑去实现。
- 适配内部 DevOps 等自动化场景较特殊需求,方便业务能快速部署和启用流量等。
自研工具,降低迁移成本
前面我们也提到了,之前公司的业务都是部署在 NGINX 集群当中,运行得也比较稳定了。所以当我们将基础架构更换到 APISIX 时,对于一些原本使用 NGINX 的业务部门来说就会存在一些抵触心理。因为一旦需要配合基础架构去更换这些底层组件,就会涉及到一些自身业务上的影响和收益等,比如工作量的增加或者系统的不稳定表现。
所以如何在公司内部去推动业务部门进行配合架构演进,也是一个非常重要的环节。我们自己的经验总结了如下几点:
- 先找一个合作部门的业务,服务好该业务部门,利用好的效果反馈来树立标杆。同时提供技术上的人员指导和辅助,为后续的运维服务打下基础。
- 在本身架构搭建中,打造对于业务层面更易用的控制面系统,方便业务接入。比如前文提到的去掉 etcd 进行自研控制面,就是考虑到了这个因素。
- 提供从 NGINX 配置一键切换到 APISIX 配置的自动转换能力,将演进成本降低。为此我们专门开发了一套系统,业务方只需输入域名,就可以把相关 NGINX 上的服务和上游等配置信息拉取过来。然后经过简单的逻辑转换与关联后,即可自动发布。
虽然做这么一套自动化配置系统困难较大,但我们还是尝试去做了并基本实现了公司内部业务的一些实际需求。比如进行 location 与 upstream 的转换与绑定、把 NGINX 关键字转换成 APISIX 插件等,目前仅把在 NGINX 上使用的一些常规配置转换成了插件使用。
当然这个转换成功率并不一定是完全契合的,因此我们在这套系统中也增加了确认环节。如果在转化后觉得并不完全适用 APISIX 的一些配置细节,还可以自行进行少量修改。从而依赖这套工具,去最大程度地降低各业务部分的迁移工作量。
自研集成测试,解决版本升级问题
vivo 是从 2021 年年中基于 APISIX 2.4 版本进行改造并陆续上线的,在今年 Q2 阶段已升级到 2.13 版本。在从 2.4 升级到 2.13 版本的过程中,在业务上也是遇到了一些问题。主要涉及到 APISIX Lua 和 OpenResty 相关的部分。
在 APISIX 的 Lua 部分,得益于 APISIX 模块化的组织方式,把我们自己修改的代码合并到 APISIX 高版本分支中,并不算麻烦。再通过完整的回归测试后,比较轻松地完成了升级。
而在 OpenResty 部分则踩坑比较多。APISIX 升级的过程中,OpenResty 也在升级,差不多一年升级一个版本。由于我们公司使用了较多的 Patch 包和一些非常用功能 (如 QAT 等),Patch 过多就会出现一些代码冲突等问题,导致该组件的后续升级比较费时费力。
为了解决上述问题,我们也进行了前文提到的一些控制面与数据面的改造。同时为了保证这些改造是运行完美的,就需要去进行相关的测试。但是如果是单纯利用 APISIX 的测试场景则只会顾及到 APISIX 单个模块,由于我们已经对控制面进行了比较大的改动,所以在这种情况下,我们使用了 Python 的 robot framework 插件来打造了自研的系统集成测试。同时由于 Python 语言的普适性,对于开发和运维人员也非常友好。
APISIX 使用心得与未来计划
《Google SRE》书中提到过,“正常运行是无数种异常情况中的一种异常”,软件能够保持正常地运行,其实是非常困难的。在使用开源产品 Apache APISIX 一年多的时间里,我们也慢慢感悟出了一些技术使用上的心得。
在使用开源产品时,心态一定要开放,不能因为出现一点点问题就开始到处抱怨。在出现问题时,要抱着积极改进与合作的心态。虽然任何软件都不可避免出现问题,但本身作为一个 Apache 的顶级项目,至少在代码质量和流程测试中都是非常有保障的。
因此在使用中遇到问题时,可以优先考虑是否自己正确地使用了相关功能,先自己去寻找原因。如果本身没有充足的时间成本和技术实力,就可以去寻求社区的帮助。得益于 APISIX 的社区活跃,我们在社区里提的很多 issue 都及时得到了响应与跟进。
同时在使用 APISIX 的过程中,我们自己其实做了非常多的改造。因此在这个过程中,我们也非常重视测试环节,只有足够的测试才能保证代码的正常运行。
当然在使用 APISIX 的这一年多的时间里,我们也在积极探索与发现更多 APISIX 的功能场景。在后续使用计划中,我们将开拓以下方向:
推动 APISIX 从 HTTP 流量网关扩展到 API 网关,这点是我们公司明年的计划之一。比如使用 APISIX 将 HTTP 协议转发到后端的 Dubbo、gRPC 或者 MQ 上进行协议转换,或者使用 API 网关的一些通用功能(限流、熔断、鉴权等)。
加强 NGINX 与 OpenResty 的自建能力。目前开源的 NGINX 社区已经不活跃了,对于一些功能的支持不及时,不利于公司统一接入层的未来发展趋势。同时我们也一致致力于提高公司内部对于 APISIX 的产品使用熟悉度,希望后续也能和 APISIX 社区一起协同共建一些功能。
拥抱服务网格趋势。随着云原生趋势的发展,服务网格领域也开始变得热门起来。但是在我个人看来,服务网格距离大部分公司还比较遥远,目前还很难把这套东西应用起来。但如果将来有一天我们真的需要启用这一块,就需要从现在就打好基本功。所谓的基本功就是流量治理和服务治理这种基础能力,把他们建设地更好,去迎接未来技术趋势的变化。